SolrCloud is the name of a set of new distributed capabilities in Solr. New Solr provides the highly scalable, fault tolerant, distributed indexing & search capabilities, near real-time search, centralized cluster configuration & management.
SolrCloud is the name of a set of new distributed capabilities in Solr. New Solr provides the highly scalable, fault tolerant, distributed indexing & search capabilities, near real-time search, centralized cluster configuration & management.
- Bird Eye: SolrCloud vs Solr
- SolrCloud Article’s
- Notable Improvements in Upgraded Versions
- SolrCloud v4.5.x
- SolrCloud v4.4.0
- SolrCloud v.4.3.x
- SolrCloud v4.2.x
- SolrCloud v4.1.0
Distributed Search – Terminology
Cluster: Set of Solr nodes managed as a single unit
Node: A JVM instance running Solr
Partition: Subset of the entire document collection, It just a single solr core
Shard: A Partition needs to be stored in multiple nodes as specified by the replication factor. All these nodes collectively form a shard. A node may be a part of multiple shards
Leader: Each Shard has one node identified as its leader. All the writes for documents belonging to a partition routed through the leader
Collection: One or more Shards/Replicas are arranged into Collection
Replication Factor: Minimum number of copies of a document maintained by the cluster
Transaction Log: An append-only log of write operations maintained by each node
Bird Eye: SolrCloud vs Solr
- SolrCloud or Classic Solr determined by zkHost parameter on startup
- Zookeeper, stores coordination and configuration information for the cluster
- The Solr configuration files like schema.xml and solrconfig.xml are stored in ZooKeeper, instead of File System
- SolrCloud eliminates the master-slave specifics, and automates both update and search seamlessly
- Narrowed solr configuration, just solr.xml requires in the solr cores. The other solr configuration’s is read from Zookeeper
- Collection API’s and CoreAdmin API’s for manage & create one
- Update log for durability and recovery, the special _version_ field to help with some of the these points, the coordination (election of overseer & shard leaders)
- Replication factor comes into play – minimum no. of copies of a document maintained by the cluster.
- Near Realtime search support through soft commits and handler ‘/get‘ return latest stored field values. Note: relies on the updateLog feature
- Distributed search across collections as long as they are compatible (for example: across geo’s search – multiple collections)
- Queries sent to any node automatically perform a full distributed search across the cluster with load balancing and fail-over (also we can make of shards.tolerant=true to return just the documents that are available in the shards that are still alive)
- Updates sent to any node in the cluster and are automatically forwarded to the correct shard and replicated to multiple nodes for redundancy. Typically suggested to send to Leader directly, for that make use of ‘Smart SolrJ client (CloudSolrServer) that knows to send documents only to the shard leaders’
- Improved Admin Interface for management and error reporting (its for both classic Solr & SolrCloud)
- Brings new terminology’s in to Solr world, as mentioned in the terminology section
- New configurable ScriptUpdateProcessor for DIH – manipulate documents on-the-fly
- Brings new admin UI customization using admin-extra.menu-top.html and admin-extra.menu-bottom.html
- New _version_ field (updateLog depend on this field) for Near Real-time get/partial documents update
- A new spellchecker implementation was introduced solr.DirectSolrSpellchecker; it allows you to use main index to provide spelling suggestions and didn’t need to be rebuilt after every commit
SolrCloud Article’s
Zookeeper Cluster (Multi-Server) Setup of-course Solr comes with embedded ZooKeeper, however not recommended for Production use.
![]()
SolrCloud Cluster (Single Collection) Deployment – here we will deploy SolrCloud Cluster in medium complexity of 3 Shard(s) with replica(s) [replication factor 3], 3 Instances of Tomcat Servers for Solr Node(s) and 5 Replicated servers in ZooKeeper ensemble.

![]()
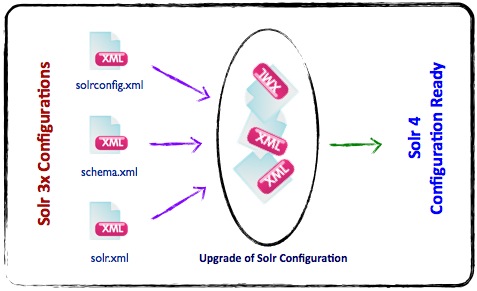
Upgrade/Migration of Solr 3.x to Solr 4 – here we will get into steps involved in migrating Classic Solr 3.x into brand new Solr 4 aka SolrCloud.